
In general when designing a fact table I’d always aim for the most detailed level of data (lowest grain) possible. It’s always easier to roll up data than to increase the detail level of data later so best to include it up front. For timetabling data this may mean expanding a very compact schedule record to vastly more rows. But even for millions of rows it’s still worth going as detailed as possible to make the reporting easier. If we imagine a schedule similar to that used by Scientia where a single record defines all instances of an activity:
| activity | 1 |
|---|---|
| start_date | 08-SEP-2020 |
| start_time | 10:15 |
| duration | 8 |
| weeks | 0101010101010000000000000000000000000000000000000000 |
Here start time and date specify the start time of the first scheduled instance of an activity. Duration is an integer specifying the length of the activity in 15 minute chunks. And weeks is a 52 character string specifying all the weekly instances of the activity. In this example activity 1 is two hours (8 x 15mins) and is scheduled six times starting on 8th September and every two weeks after. This is a very efficient way of recording the schedule but is very hard to report from. So I want to expand the schedule into this much more BI friendly structure:
| activity | time_slot_start | duration |
|---|---|---|
| 1 | 08/Sep/2020 10:15 | 15 |
| 1 | 08/Sep/2020 10:30 | 15 |
| 1 | 08/Sep/2020 10:45 | 15 |
| 1 | 08/Sep/2020 11:00 | 15 |
| 1 | 08/Sep/2020 11:15 | 15 |
| 1 | 08/Sep/2020 11:30 | 15 |
| 1 | 08/Sep/2020 11:45 | 15 |
| 1 | 08/Sep/2020 12:00 | 15 |
| 1 | 22/Sep/2020 10:15 | 15 |
| 1 | 22/Sep/2020 10:30 | 15 |
| ... | ... | ... |
Here every 15 minute slot of scheduled time has a record. So for the above example there will be 48 rows (6 instances * 8 fifteen minute slots). First I’ll expand each record to one row per instance (6 in the example). This query joins a table of activity schedules to an integers table to get 52 rows per schedule – one for each week.. The where clause filters out any weeks where there is no instance of the activity.
select a.activity
, a.duration
, CHARINDEX('1', a.weeks, 1) first_week_number
, i.number week_number
, a.start_date + start_time first_time_slot_start
from activities a
join integers i
on i.number <= 52
where substring(a.weeks, i.number, 1) = 1
The output of the query returns the activity ID, duration, the week number and date/time of the first instance of the activity and the week number of the each instance. For the example above it would look like:
| activity | duration | first_week_number | first_time_slot_start | week_number |
|---|---|---|---|---|
| 1 | 8 | 2 | 08-SEP-2020 10:15 | 2 |
| 1 | 8 | 2 | 08-SEP-2020 10:15 | 4 |
| 1 | 8 | 2 | 08-SEP-2020 10:15 | 6 |
| 1 | 8 | 2 | 08-SEP-2020 10:15 | 8 |
| 1 | 8 | 2 | 08-SEP-2020 10:15 | 10 |
| 1 | 8 | 2 | 08-SEP-2020 10:15 | 12 |
Next I’ll expand these records into 15 minutes slots. Joining to integers this time to get one row for each 15 minute duration the query outputs the activity ID, the duration of the slot (always 15 minutes) and the start time of the slot – this is calculated by adding the number of weeks after the first time slot start to this date. And then the number of 15 minute intervals. Here’s the query using the prior query as the subquery.
select sub.activity , dateadd( minute, (i2.number - 1) * 15, dateadd(week, week_number - first_week_number, sub.first_time_slot_start )) time_slot_start , 15 duration_in_minutes from (subquery) sub join ext.integers i2 on i2.number <= sub.duration
This gives the output discussed above. For simplicity’s sake I’ve left off the other foreign keys that you would expect in this table such as location, modules and lecturers. With these included the structure makes answering most questions about how time is scheduled very simple. I’d also define a calendar dimension with a 15 minute slot grain to join to. It doesn’t however tell us anything about time scheduled for specific students. Adding a student ID and expanding the query further so that there is a record per activity timeslot per student will produce a lot more rows. I’d estimate the resulting number of rows will be 500 times the number of scheduled activities. Still a tool like Power BI should still make quick work of this. Again this query uses the prior as the subquery.
select activity , time_slot_start , duration_in_minutes from (subquery) sub join activity_students as on as.activity = sub.activity
Of course while I can now report student hours I can’t report at activity level. So I’ll need to have two fact tables, one at the activity / timeslot grain and one at activity / student / timeslot grain. Actually I could add an additional column to the activity / student / timeslot table:
Activity Duration = StudentActivity[duration] / CALCULATE(DISTINCTCOUNT(StudentActivity[student_id]), ALLEXCEPT(StudentActivity, StudentActivity[activity]))
This measure would sum up at activity level fine:
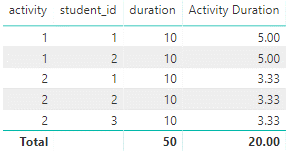
However in general I dislike this approach. The Activity Duration measure can be used with the student dimension but doesn’t really have any meaning in this context. I think that maintaining two fact tables of different grain is better for the clarity of purpose it provides.